
As over 22 mil. people have undergone mail-order DNA testing through AncestryDNA since their rolling out in 2012, it is quite clear that the majority of their consumers were all curious about where they came from. With that being said, how accurate are these test results and is there any room for error? What happens if you get unexpected results?
Between their two big features, Ethnicity Estimates and DNA matches, there is definitely some room for improvement. But can Ancestry DNA results be wrong? Yes and No. Let’s dive into it.
Can ethnicity estimates be wrong?
Note that AncestryDNA offers the Ethnicity Estimate explicitly with the word “estimate” in the title. Rather than running around telling people you’re 33% Scottish, you should do your due diligence in determining how these estimates are created.
AncestryDNA and other DNA sites have a database that I like to refer to as their “reference panel”. These panels are compiled of thousands of base samples from people who appear to have, in simpler terms, 100% genetic makeup of a single ethnic group. Is it likely that there is such a thing as someone who is 100% Scottish, English, French or German? Well, not really. With thousands of years of wars, border changes, and pillaging, things tend to be quite complex. However, if an individual has a long proven lineage remaining within close proximity of an area that corresponds with a specific ethnic group then that person would likely make a great panelist.
For many people, the big draw for ordering the product is the ethnicity estimate. It is one of their biggest marketing features for the product. This makes it so that when curious individuals who might not be interested in their family tree order the kit, they log in to see their results, take it at face value and never log back in. When I first got my results, I did the same thing. If you happen to be one of those people, I highly suggest to log back in and update your results. How do these results get updated?
As Ancestry updates their reference panel, they are able to hone in on more groups of people. In the last few years they have even changed some of their categories and combined them. For instance, they now have “Germanic Region” rather than just “German”. As borders between France and Europe have switched back and forth over thousands of years, how do we diversify these regions ethnically? Well, we can’t. It is definitely not an exact science.
My favorite example is this –
France and Germany are comparable to the sizes of Washington State and Oregon. How can we tell the difference between an individual who lived in Washington apart from one who lived in Oregon? Well, DNA has been around much longer than man-made borders, so each update provides a better in depth analysis of their reference panels to help resolve situations like this.
As science improves in the genetics space, your AncestryDNA ethnicity estimate is likely to grow more and more accurate.
Can DNA Matches be wrong?
AncestryDNA has the largest online database of users who opt in to see who they share DNA with. These matches are displayed in your matches panel which allow you to browse through your matches to see how much DNA (in cM’s – Centimorgans) you share with them. Ancestry displays these matches from highest to lowest and the algorithm sorts them under the following:
- Parent/Child
- Close Family
- Extended Family (1st – 2nd Cousins & 2nd – 3rd Cousins, 3rd – 4th Cousins)
- Distant Family (4th – 6th Cousins)
In each individual match you may or may not see a tree associated with them. If you and them share a public tree which you have linked to your DNA kit you will be able to see where exactly you both share. Keep in mind this data can be messy if your DNA matches do not have their tree’s correct. This is a situation where Ancestry users are the culprit for skewed data rather than Ancestry themselves. However, there is one place where Ancestry gets very confusing and it is, again, up to the user’s due diligence to sort through the data.
The algorithm does not get it right all the time. This is not a jab at Ancestry it is just a fact. By displaying the cousins the way they do (as listed above) they fail to take into account half cousins and cousins removed. This means that a match under “Extended Family” 4th – 6th cousins might be much closer than Ancestry shows. This is a huge thing to remember when searching for biological family or working on unknown parentage and adoptee cases. If you sign in to Ancestry and don’t have super close matches, don’t be discouraged. Just dive into the data and you will find more answers than you would have ever expected.
In order to determine whether or not the algorithm is accurate in their categorizing of your DNA matches, you have to approach each match individually. There are many tools online that help you determine this but my favorite, and the most user friendly, is the Shared cM Project from DNAPainter.com. By placing the shared amount of cM between you and your match, this algorithm produces the most likely scenario through which you and this cousin relate. One of my favorite examples of this tool in practice is of Johnny and his “extended family” DNA match Alice.
Johnny and Alice Example
Johnny shares 62 cM with a DNA match named Alice who his consumer website lists as a “4th – 6th cousin”. Johnny turns to the shared cM tool to determine how it is they likely relate to one another. The shared cM tool populates the following:
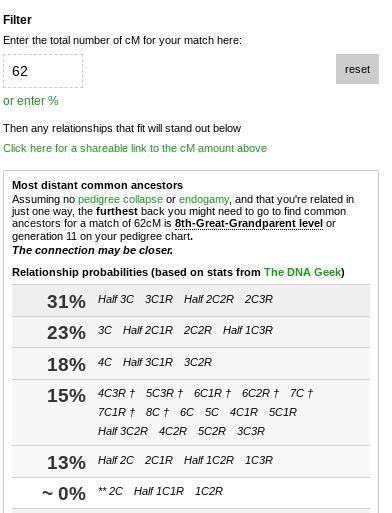
Johnny, from this tool, is visually able to determine that he is most likely (31%) related to Alice is a 2nd Cousin twice or three times removed or a Half 3rd Cousin or 3rd cousin once removed. Using this data they are able to determine that Alice and Johnny share a set of great great grandparents. Their generations are quite different and, with some family research, they are able to determine they are 2nd cousins 3 times removed.
Not a 4th – 6th Cousin.
Johnny learned to approach each DNA match independently in order to pinpoint their relationship.
With the amount of data Ancestry sorts through and implements into their algorithm, it is probably much easier for them to not include halves or removed into their cousin categorization. Perhaps in the future it something they might work on implementing but, until then, it really is not that difficult to determine your relation to cousins through other online tools. Especially when they’re free.
Final thoughts
Pardon my ominous “Yes and No” comment at the beginning of this article in relation to whether or not AncestryDNA results can be wrong. I hope you can understand why I made that comment. Ancestry will never be untruthful to their consumers as they talk a very big talk about “customer obsession” and they want to ensure that their consumers are getting the most accurate and up-to-date genetic information all the while maintaining a two-way street of trust. See my complete Ancestry DNA review.
Just remember that when viewing your ethnicity estimate that it is just an “estimate” and keep on checking your account for updates. Also, remember to do your due diligence in determining whether or not you are more closely related to the DNA matches that populate within the “extended family” category. Through updates and advancements in DNA technology, Ancestry is going to provide the most accurate data to its consumers. Just be patient, roll up your sleeves and jump on in!

